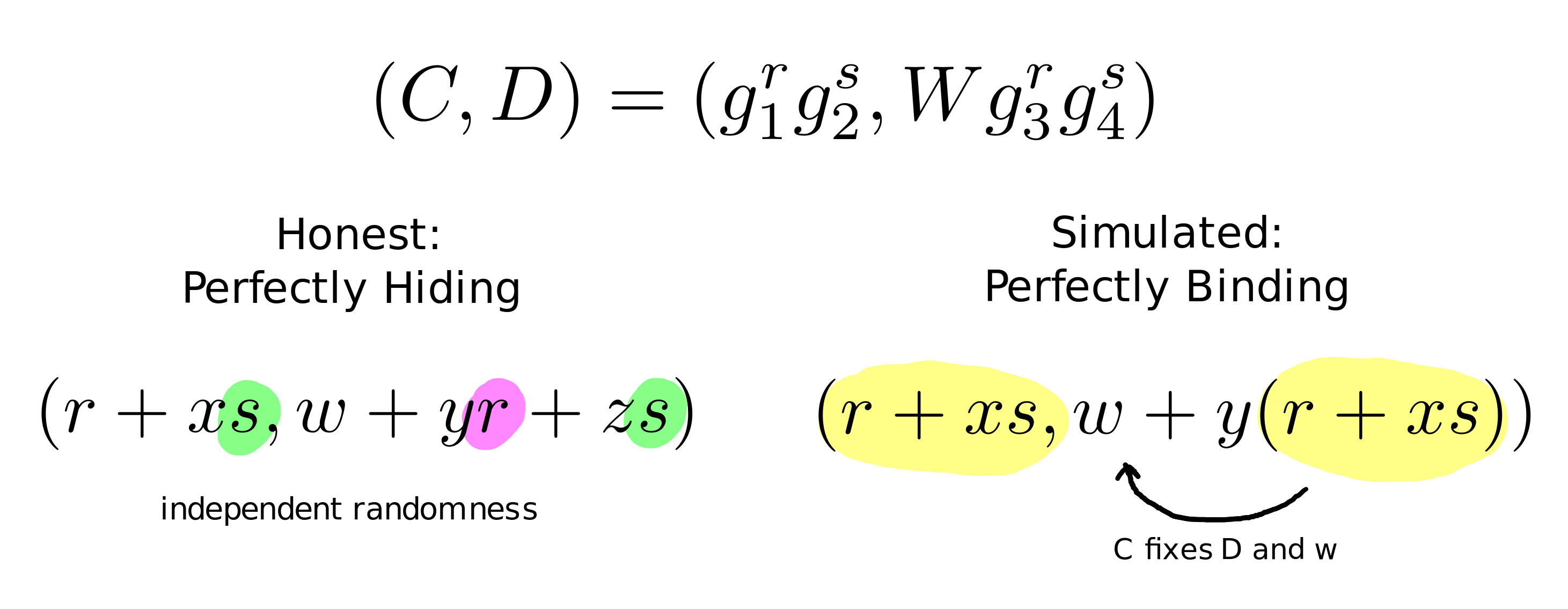Mikhail Volkhov, Dimitris Kolonelos, Dmitry Khovratovich, Mary Maller | June 6, 2022
Groth-Sahai (GS) proofs are a zero-knowledge proving technique which can seem daunting to understand. This is because much of the literature attempts to generalise all possible things you can prove using GS techniques rather than because the proofs are overly complicated. In fact GS proofs are one of the simplest zero-knowledge constructions. For statements about group elements in pairing based groups, they are ideal because there is no heavy reduction to an NP constraint system, and this makes the prover very fast. Security wise they also rely on much more standard assumptions than SNARKs and thus are more likely to be secure.
In this post we will walk through an example Groth-Sahai proof and attempt to make the explanation accessible to a general cryptographic audience. Specifically we discuss how to prove that an ElGamal ciphertext contains 0 or 1. Our example includes the improvements by Escala and Groth. Prerequisites include knowledge about what a zero-knowledge argument is and what Type-III pairings are (but not how they are constructed).
And for those interested in experimenting with GS proofs in practice we have written a simple implementation in python -- check it out! It includes both the example we will be going through in this paper, and the more general proving framework that you can use to construct proofs for your language.
ElGamal in Pairing Product Equations
In order to prove that an ElGamal ciphertext contains 0 or 1 we must first arithmetise this statement into a form that is compatible with GS proofs. GS proofs take as input pairing-product equations; pairing product equations can be seen as the equivalent of arithmetic circuits in the sense that they arithmetise the relation that we are trying to prove. Thus in this section we show how to represent our statement using pairing product equations. In later sections we will show how to prove that these equations are satisfied under zero-knowledge.
Notation and Pairings
Recall the standard property of pairings: e(ga,hb)=e(g,h)ab We denote the first source group by G1 and the second source group by G2. Elements from G2 are denoted with wide hat like E. We will write Θ=gθ and D=hd trying, where it's possible, to use lowercase letters for exponents of the corresponding capital letter element.
Pairings allow us to define quadratic equations in the logarithms of the arguments, e.g.
If you have not worked with pairings with multiple bases, see this explanation:
Collapsible: On Pairings with Multible Bases
As later we will employ multiple bases and not just g,h, pairing equations will also work "in parallel" for all pairs of bases from G1 and G2.
Consider the following example.
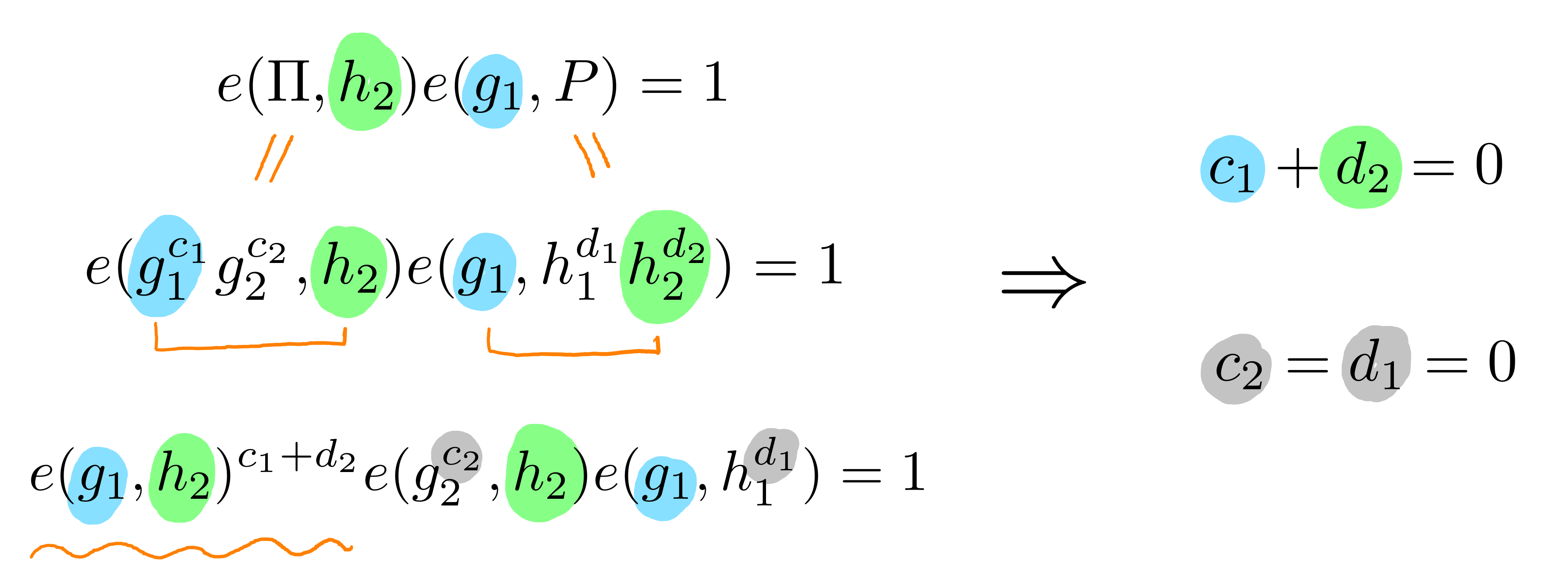
By bilinearity of the pairing e(g1ag2b,h1ch2d)=1 is equivalent to: e(g1,h1)ac⋅e(g1,h2)ad⋅e(g2,h1)bc⋅e(g2,h2)bd=1 In such a case we will always have ac=ad=bc=bd=0 when all gi and hi are chosen independently and uniformly at random.
Here is an example of how it works:
ElGamal Verification in Pairing Equations
We first present our solution for arithmetising the statement "This ciphertext contains 0 or 1" directly and after explain the intuition for how we derived these equations. Let g1 generate G1, and pk=g1sk. Consider a (lifted) ElGamal ciphertext
CT=(CT1,CT2)=(g1r,M⋅pkr)(1)
Then M=g1m is either (g1)0 or (g1)1 if and only if there exist witnesses W1,W2,W3 such that
Note that the witness components (W1,W2,W3) must be kept secret because they reveal information about the message M.
Our purpose now is to explain how we arrived at the above set of pairing product equations and along the way to illustrate the design constraints that the GS proving system presents us with. Arithmetising statements is an art that Daira Hopwood is exceptionally skilled at (check out the Zcash spec, Appendix A, for many cool arithemetisation tricks). Alas, we are not Daira so please bear with us even if our solution is not optimal.
One characteristic feature of GS proofs is that all secret witness components must be group elements rather than field elements. So our secret that we want to keep hidden cannot be field elements 0 or 1 or r, but must instead be group elements g10 or g11 or g1r. For our ciphertext to encrypt 0 or 1 we thus desire that m∈{(g1)0,(g1)1}. Turning to the equation (1) we have that this condition that is equivalent to
CT2⋅pk−logCT1∈{(g1)0,(g1)1}(2)
where logarithm is taken with base g1. Denote W2=g1w2=CT2⋅pk−logCT1 We wish to check that w22−w2=0. Our one and only method of checking constraints is using pairing equations. We cannot pair W2 with itself because we can only pair G1 elements with G2 elements. Thus we choose to "bridge" w2 into G2 by introducing an additional group element W3=h1w3 such that
w2w2w3−w2==w30
where w2 is a logarithm of some G1 element W2 and w3 is a logarithm of some G2 element W3.
That first condition in (3) that CT2⋅pk−logCT1=W2 currently does not look very much like a pairing product equation. We cannot use logarithms in PPEs, so we need an alternative method for arithmetising that logCT2−logCT1⋅logpk=w2 As CT1,CT2,pk are all in G1, we make another bridge:
Combining all our pairing equations together we arrive at our final pairing product equation for arithmetising that (CT1,CT2) encrypts 0 or 1.
General Proof Structure
In this section we describe the GS setup, prover and the verifier used in representing the statement "This ciphertext encrypts 0 or 1".
Transparent Setup
We discuss how to run the GS setup. The setup does not depend on our pairing product equations at all and the same setup is used for proving any statement. It is only the prover and the verifier that depend on the pairing product equation explicitly.
NIZK proofs are constructed with a common reference string (CRS), that is used for both producing and verifying proofs. In GS proofs the CRS is constructed using public randomness and therefore they are said to have a trustless setup (this is a positive thing because we do not have to trust a third party or MPC that replaces it, like with many SNARKs). The GS CRS consists of eight independent elements --- four in each group.
In practice these elements are typically sampled as the output of a hash function, and the seed is published so that anyone can verify the setup procedure. It is permitted and encouraged to have fun (not too much fun) when choosing the seed and we sometimes like to use the opening lines of famous books.
We will reuse the generator g1 for our ElGamal ciphertext which helps us to simplify the structure of prover and verifier.
Commitments to Witnesses
We now describe our GS prover. The prover aims to show the existence of a witness that satisfies the pairing product equations. The witness is secret and cannot be revealed directly. Thus instead the prover commits to the witness, and proves that the committed witness satisfies a related set of pairing product equations. We discuss the form of this commitment before we present the related set of equations.
The prover computes two elements using an algorithm that looks a lot like ElGamal encryption. To commit to W∈G1 it chooses random field elements r,s, sets C=g1rg2s,D=Wg3rg4s and returns (C,D). We have expressed the commitment with respect to G1. To commit to elements in G2 we use the same method with respect to the generators (h1…h4) instead of (g1…g4).
Typically when we present this commitment scheme to cryptographers their immediate response is "why two generators?" or "why not use Pedersen commitments?". The answer to this question is highly nuanced and answering it here would disrupt the flow of this explanation. Thus we're not going to. But as a teaser, we will say that Groth and Sahai describe this commitment scheme as one that either satisfies hiding or binding depending on how the setup parameters are chosen.
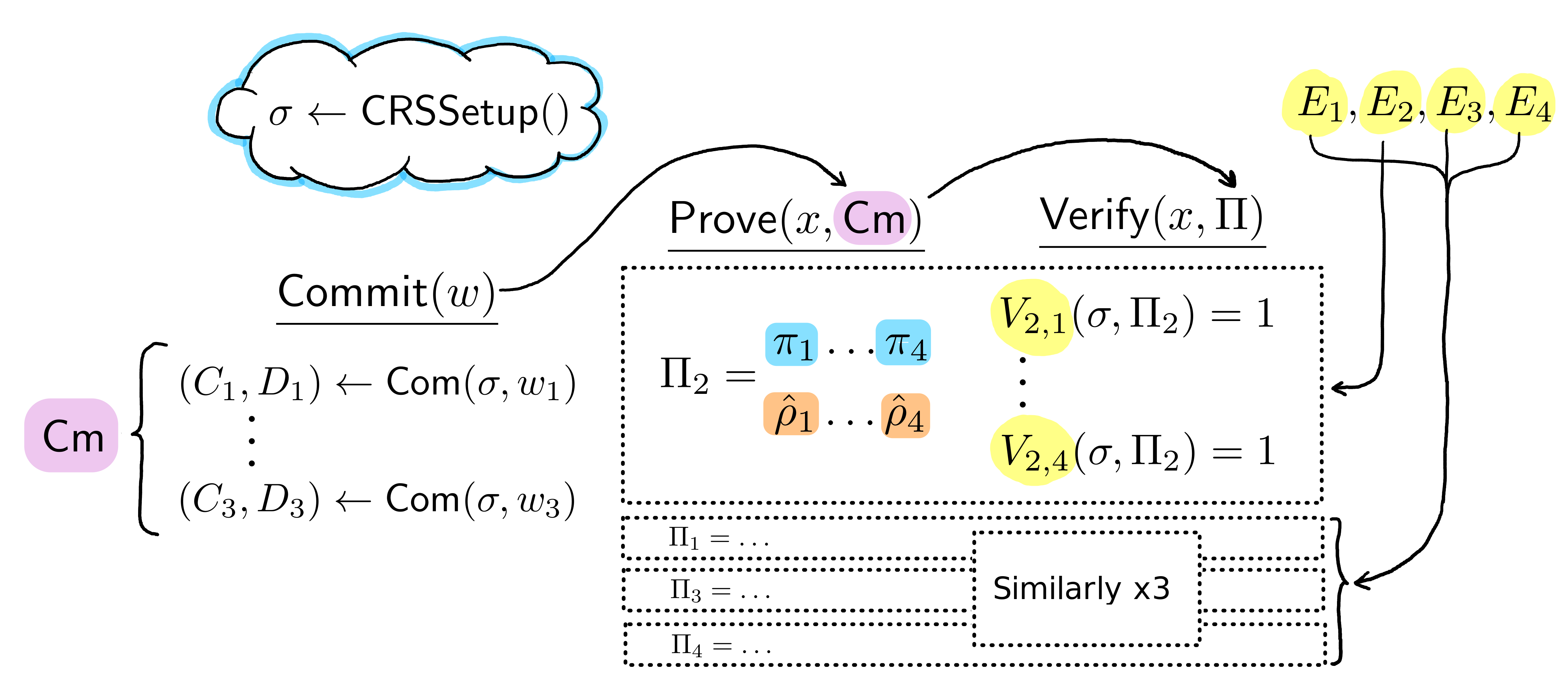
Now, in our particular case of ElGamal encryption, we commit to our witness (W1,W2,W3) once for all equations E1−E4:
While the commitments (C1,D1,C2,D2,C3,D3) are shared across all pairing product equations, each pairing equation requires a unique set of 8 proof elements and 4 verifier equations, so forms a "sub-proof". Here, mostly to stay concise, we show and later derive the proof system (prover and verifier) only for the second equation E2. For the full system thus, prover must produce proofs for all four equations, and verifier must verify them all.
Recall that E2 has the form
e(CT2,h1)=e(pk,W1)e(W2,h1)(E2)
The honest prover needs to construct the following eight elements, where α,β,γ,δ are sampled randomly:
The reader is encouraged to attempt deriving the same equations for E1,E3 which are both easier than our case (we put our derivation for them at the end of the blog post). A more sadistical writer might also ask the reader to derive equations for E4 as an exercise (possibly hinting that it is a simple), but after having attempted this exercise for ourselves we realised that E4 is more involved due to its quadratic component. Thus at the end of this document we will actively discuss E4.
The form of proof elements and equations is somewhat homogeneous: we always have 8 proof elements and 4 verification equation per pairing equation, and the LHS of verification equations is always the same. However, the number of pairings in verification equations depends on the particular form of the pairing equation (reflected in the RHS). The commitments, as mentioned before, are generated once for all pairing equations, which amounts to 2 elements per witness element.
The following illustration shows how it works on a large scale:
Deriving Equations for E2
The intention of this section is to provide an intuitive step-by-step explanation of how the proof elements and verification equations for the pairing product equation E2 are derived. We describe our general strategy, but after that things are going to get more technical. To readers that don't fancy wading through pages of algebra, we recommend you stop reading after the general strategy is explained. To other readers who are more dedicated to understanding the magic behind GS proofs, we recommend you get comfortable with continously switching between additive and multiplicative notation because we do this a lot (we promise not in the same equation).
The General Strategy
We have a pairing product equation that the prover claims to hold for hidden witness variables. The prover cannot give the witness in the clear, this would violate zero-knowledge, but it still must tell the verifier something about its witness. The prover therefore generates a commitment which binds them to their witness without revealing any additional information.
Our general strategy now is to find an alternative set of pairing product equations that hold if and only if the contents of the commitments satisfy the original pairing product equation. Our strategy will proceed in two parts.
During our first part we search for intemediary proof elements that satisfy an intermediary set of pairing product equations if and only if the contents of the commitment satisfy the original pairing product equation. We treat soundness as if it holds unconditionally i.e. as if the only way for the prover to cancel out the randomness from the CRS is to multiply by zero. In the formal proof, we actually show that soundness does hold unconditionally provided the CRS is chosen carefully.
During our second part, we show how to randomise the intemediary proofs and pairing product equations in a way that fully hides the witness. This results in our final equations. Here we focus mostly on satisfying zero-knowledge but we must not break soundness in the process. In other words we try to ensure that a malicious verifier learns nothing from an honest prover, beyond the correctness of the ciphertext.
For arguing indistinguishability, one of the key properties we require is that the number of randomisers is equal to the number of proof elements minus the number of verifier equations. That way we can say e.g. that Element 1 is random, Element 2 is random, and Element 3 is the unique value satisfying Equation 1 given Elements 1 and 2. Thus our strategy is to add in additional randomisers to our proof elements and edit our verifier equations such that they still hold for the randomised proofs. To keep things sound we also have to add additional verifier equations to enforce that the prover doesn't abuse their newfound freedom. The other property we require is that there are no linear combinations between our randomisers such that they cancel out in undesirable ways. While deriving our equations for (E2) we are merely going to optimistically hope that this holds, but formally check that it is the case later.
The Intemediary Pairing Product Equations for Commitments
For the first part of our strategy, we must find an intermediary set of pairing product equations demonstrating that the contents (W1,W2) of the commitments
Then the logarithms of our commitments are given by
(c1,d1)=(r1+us1,w1+r1v+s1ℓ) and (c2,d2)=(r2+xs2,w2+r2y+s2z)
If we now actually look at the logarithmic equation defined by (E2) we get that
logg1CT2−sk⋅w1=w2(L2)
where sk=logg1(pk). Notice that r1,s1,s2,r2 are known to the prover while x,y,z,u,v,ℓ are not. We make no assumptions on whether sk is known to the prover or not.
Our derivation strategy is, by introducing new variables, to obtain a set of equations equivalent to L2 such that
The equations do not contain w1,w2;
The equations are bilinear, i.e. each term has at most one variable from each group.
Step 1: We first express w1 and w2 in terms of the commitments (c1,d1,c2,d2) and the randomness r1, s1,r2,s2. The commitment D1 should use the same randomness r1, s1 as the commitment C1. Therefore, we substitute r1=c1−us1 into the equation for w1 and obtain:
w1=d1−(c1−us1)v−s1ℓ
Similarly for the second commitment: w2=d2−(c2−xs2)y−s2z
Step 3: The terms logCT2,sk⋅d1,d2 are already in the pairing equation form (degree at most two, at most two elements from different groups), so we leave them alone, moving to the RHS, and swapping sides of the equation:
Now, we want the RHS summands to be in the pairing-friendly form too. Currently they are not. For example, we cannot pair C2 with g3=g1y because these are both in the same source group.
Step 4: To get the RHS into a pairing friendly form, we will introduce new elements. For each summand we introduce one proof element. For example, where y is multiplied by (c2−xs2), we introduce ϕ1′=c2−s2x. This suggests creating four additional elements:
The additional proof elements we introduced is somewhat arbitrary --- there are many (closely related if not equivalent) ways to construct GS verification equations. Now our first equation is in the following well-formed pairing-compatible form:
sk⋅d1+d2−logCT2=θ1′v+yϕ1′+θ2′ℓ+zϕ2′
Step 5: Our fifth and final step for determining the intemediary pairing equations is to enforce the previous four equations for Θ1′,Θ2′,Φ1′,Φ2′. We start by joining the first two (substituting the second into the first) and obtaining: θ1′=sk⋅c1−θ2′u Similarly, by joining the third and the fourth equations, we get:
ϕ1′=c2−ϕ2′x
Resulting Intemediary Pairing Product Equation: Putting all 5 steps together, our intemediary pairing product equation challenges the prover to find
(Proof elements in verification equations are without primes since they are considered to be formal variables.) Together these show that the commitments (C1,D1) and (C2,D2) contain witness elements W1 and W2 such that the second pairing product equation (E2) is satisfied.
We are now going to frustrate the reader by observing that the above process was rather circular. Indeed we cannot reveal Θ1′,Θ2′,Φ1′,Φ2′ in the clear: they reveal too much information about the witness and violate zero-knowledge. For example observe that
e(D2,h1)e(g3−1,Φ1′)e(g4−1,Φ2′)=e(g1m,h1)
for m our secret message. The next step, however, will not be circular and we will show how to randomise these proof components in a manner that does not break zero-knowledge. That we have really gained is that Θ1′,Θ2′,Φ1′,Φ2′ depend only on the original pairing product equations and the commitment randomness r1,s1,r2,s2. In particular they do not depend on the witness W1, W2.
A general property that is required (but not sufficient!) for zero knowledge is that number of randomisers ≥ number of proof elements − number of verification equations. Here we have 4 commitment elements with 4 randomisers and then 4 proof elements with no additional randomisers. Given 3 verifier equations this leaves us 1 randomiser short.
For the second part of our strategy, we must randomise our intermediary proofs (Θ1′,Θ2′,Φ1′,Φ2′) and pairing product equations (V1′),(V2′),(V3′) to keep the witness hidden. We do this by adding blinding factors to Θ1′,Θ2′ (order does not matter), and cancelling out the additional noise using other proof elements. Often the only way we can balance the randomised pairing equations is by adding additional proof elements. When we do this, we either add at least one new randomiser to the new proof element, or a new verifier equation which is a quadratic combinations of our other proof elements.
Step 1: We first introduce a randomiser to Θ1′. We must then edit our intemediary equations to adjust for the extra randomness. We set
θ1′′=θ1′+yα
By substituting this into the RHS of (V1′)
ϕ1′y+ϕ2′z+θ1v+θ2ℓ
we see that an additional term yαv has been acquired. This is unwanted noise that we must cancel out. To cancel the extra terms we edit ϕ1′ accordingly
ϕ1′′=ϕ1′−αv
because this term is multiplied by y. Now (Θ1′′,Θ2′,Φ1′′,Φ2′) satisfy (V1′) and do not reveal the witness.
Step 2: We edit (V2′) so that our randomised proof elements can satisfy it. The RHS of (V2′) is given by
θ1′′+θ2′u
and this has aquired the additional noise yα. We cannot hope to cancel this noise out with Θ2 because of the u multiplier. For soundness, we also want to enforce that the noise added in Θ1′′ is actually a multiple of y and does not interfere with the witness. We thus introduce a new proof element that will be paired with y blinded by an additional randomiser γ
ϕ3=−α−γu
And therefore, (V2′′) becomes
sk⋅c1=θ1′′+θ2′u+yϕ3(V2′′)
Now ϕ3 does not prevent (V2′) from being satisfied whenever (V2′′) is satisfied because y is an unused basis. To make this equation balance we modify Θ2′ and get
θ2′′=θ2′+γy
and we see (V2′′) is still satisfied.
Step 3: We look back at (V1′) with respect to our randomised proof element Θ2′′. By substituting this into the RHS of (V1′)
ϕ1′′y+ϕ2′z+θ1′′v+θ2′′ℓ
we see that an additional term γyℓ has been acquired. This is unwanted noise that we must cancel out. To cancel the extra terms we edit ϕ1′′ accordingly
ϕ1=ϕ1′−αv−γℓ
because this term is multiplied by y. Now (Θ1′′,Θ2′,Φ1,Φ2′) satisfy (V1′) and do not reveal the witness.
Step 4: We edit (V3′) so that our randomised proof elements can satisfy it. The RHS of (V3′) is given by
ϕ1+xϕ2′
and this has aquired the additional noise −αv−γl. To cancel out the extra noise we introduce two new proof elements that will be paired with v and l respectively, and blind them with β and δ
θ3=α+xβθ4=γ+xδ
And therefore, (V3′) becomes
c2=θ3v+θ4ℓ+ϕ1+xϕ2′(V3)
Now Θ3,Θ4 does not prevent (V3′) from being satisfied whenever (V3) is satisfied because v,ℓ is an unused basis. To make this equation balance we modify ϕ2:
ϕ2=ϕ2′−βv−δℓ
and we see (V3) is still satisfied.
Step 5: We look back at (V1′) with respect to our randomised proof element ϕ2. By substituting this into the RHS of (V1′)
ϕ1y+ϕ2z+θ1′′v+θ2′′ℓ
we see that an additional term −βzv−δzℓ has been acquired. This is unwanted noise that we must cancel out. To cancel the extra terms we edit Θ1′′ and Θ2′′ accordingly
θ1=θ1′′+βz=θ1′+αy+βzθ2=θ2′′+δz=θ2′+γy+δz
Now (Θ1,Θ2,Φ1,Φ2) satisfy (V1′) and do not reveal the witness.
Step 6: We edit (V2′′) so that our randomised proof elements can satisfy it. The RHS of (V2′′) is given by θ1+θ2u+yϕ3 and this has aquired the additional noise βz+δzu.
We shall need to add a proof element which is paired with z to cancel the noise. We cannot balance any additional randomness that this new element introduces because Θ1 and Θ2 already both have z components. Thus for our final proof element to not use up a randomiser we instead add a verification equation. See that
βz+δzu=xz(θ3+θ4u+ϕ3)
We thus introduce a new proof element
ϕ4=−β−δu
and a verification equation
0=θ3+θ4u+ϕ3+xϕ4(V4)
Now (V2′′) becomes
sk⋅c1=θ1+θ2u+yϕ3+zϕ4(V2)
We do not need to edit (V1′) or (V3) because no proof elements have been edited.
Resulting Verifier Equations: Putting everything together, we have the following eight proof elements
The verification equations (V1),(V2),(V3),(V4) given in Section 3 are exactly equal to what we have just derived.
This completes our explanation for how the prover and verifier for (E2) are derived. In the next sections we will dive into the security rationale behind this construction, and give more formal arguments of security than simply stating that we have the correct number of randomisers. Still, if you are constructing a zero-knowledge proof but have less randomisers than proof elements minus verifier equations, then it is time to become very suspicious of your result.
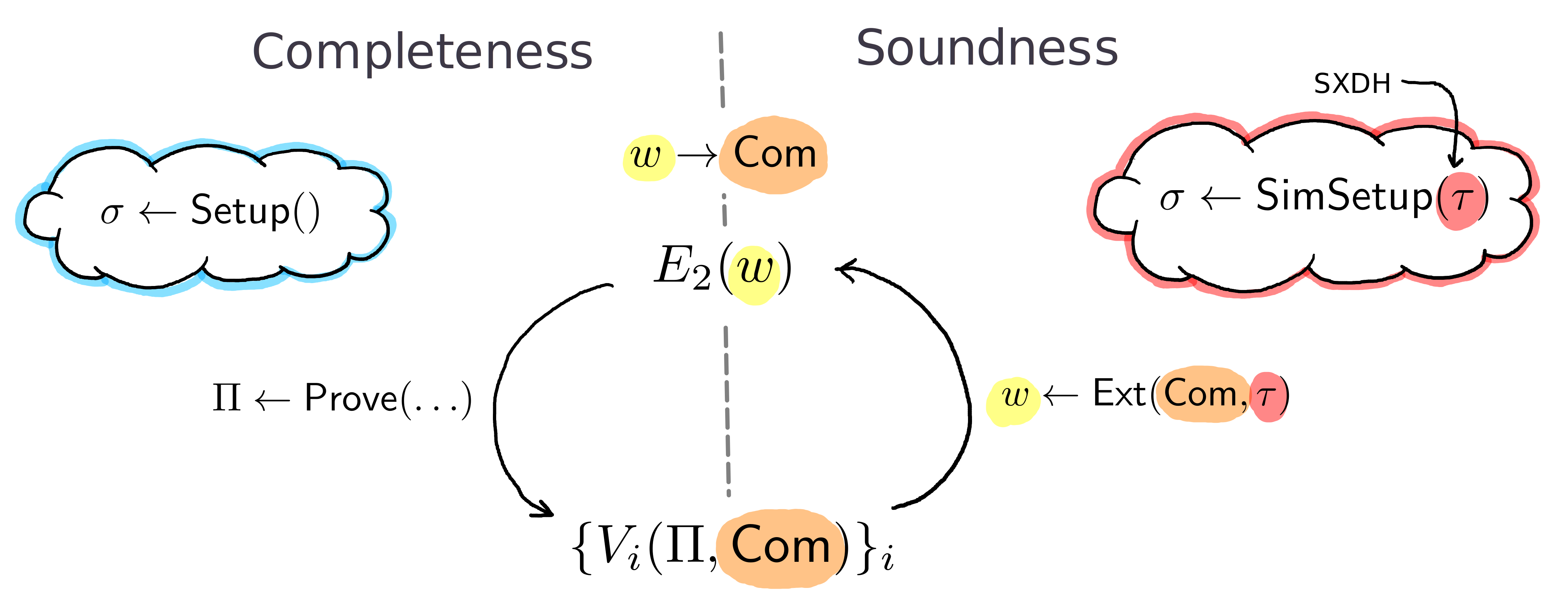
Proving Security
The previous section explains how, intuitively, one should arrive at GS equations, using E2 as an example input equation. Now we explain (and formally prove) why the resulting system of equations satisfies completeness, soundness, and zero-knowledge.
Completeness
(Does anyone ever actually prove completeness? The proofs satisfy the verifier in our implementation...)
Completeness of the proof system means that every honestly-generated proof verifies with probability one. That is, if W1,W2,W3 satisfy E2, then Π=(Θ,Φ) satisfies V1∧V2∧V3∧V4. It can be easily seen that this holds by construction because proof elements that satisfy the original equations (commitment validity + (E2)) must also satisfy the derived equations.
Soundness
Soundness of the non-interactive proof system means that for any adversarially constructed proof that verifies there exists a witness to the given relation (in our case, the witness is (W1,W2)). The GS proof that we presented, like with most of the common zero-knowledge proofs today, is computationally sound assuming that a cryptographic problem is hard. The assumption here is the SXDH (Symmetric External Diffie-Hellman): nobody can tell the difference between random (g1,g2,g3,g4) and (g1,g1x,g1y,g1xy) in G1 and analogously for G2. Looking ahead, this will help us argue that a commitment setup ((g1,g1x,g1y,g1xy),(h1,h1u,h1v,h1uv)) looks similar to ((g1,g2,g3,g4),(h1,h2,h3,h4)).
The intuition about soundness can be found in the way the equations V1…V4 were constructed. We built them such that when the original E2 holds for some witness elements, the final {Vi}i hold too (E2⇒{V1…V4}). But the transformations that we applied to our equations are in fact one-to-one, and it is also true that when {Vi}i hold, E2 holds for some witness ({V1…V4}⇒E2).
To formally demonstrate soundness, the only cryptographically elaborate detail is to show that (C1,D1),(C2,D2) are always commitments that contain some W1,W2 and not some stray elements. This is where SXDH comes in play. The reader can follow a more formal assertion of soundness in the hidden section next.
Collapsible: Commitment scheme under standard and SXDH setups.
The commitment scheme with the standard setup, where all base elements are randomly picked, is perfectly hiding and computationally binding. Because of this, when we see a commitment under standard setup, intuitively, we cannot claim that anything is "contained" inside of it, which is necessary for the existentially qualified soundness statement: "for every verifying proof there exists a witness". We only know that for whatever was put in there, it's computationally impossible for the prover to find another element that this commitment opens to. Put more explicitely, upon seeing a commitment(C1,D1) we cannot extract some unique W1 such that the commitment contains (h1r1h2s1,W1h3r1h4s1) because there are multiple solutions.
When instantiated with the SXDH setup though (g1,g1x,g1y,g1xy),(h1,h1u,h1v,h1uv), the commitment scheme becomes, in contrast, computationally hiding and perfectly binding. Comparing to the previous situation, we know that for every commitment, there is exactly one valid element committed that can lead to this outcome (one-to-one correspondence). This is just as an encryption scheme (actually it is literally ElGamal encryption). This means that we, knowing the alternative setup trapdoors (x,y,u,v), can decrypt the commitments and obtain the witness.
Our strategy for proving soundness is therefore to show that we can extract a witness that satisfies E2 from any proof that is valid for the SXDH (=subverted) setup. One extracts a witness by decrypting the commitments (see step 1 below), and shows it is a witness by checking V1-V4 equations (step 2 below). The strategy proves the soundness for not only SXDH setups but for any setups that are indistinguishable from such. The SXDH assumption tells us that any random setup should be as such, and thus we prove the soundness. Now back to the witness:
First of all, each pair of elements (C2,D2)∈G1×G1 is a proper perfectly binding commitment. It is easy to see that with c2=r2+xs2 we have d2=w2+yr2+xys2=w2+yc2. This means that in honestly constructed commitments under SXDH the second element is always deterministically defined by the first. As argued for any (C2,D2) there always exist w2 such that (C2,D2)=Commit(g1w2,(r2,s2))=(g1r2+xs1,g1w2g1y(r2+xs2)) for some r2,s2.
Similarly, (C1,D1)=Commit(h1w1,(r1,s1))=(h1r1+us1,h1w1h1v(r1+us1)).
Now we review V1…V4 in logarithms with commitment representations given:
Performing arithmetic operations on both sides of each equation simultaneously, V1−V2⋅v−V3⋅y is equal to:
−v(yϕ3+xyϕ4)−y(θ3v+θ4uv)=w2+sk⋅w1−logCT2
LHS of which is exactly vyV4, and since V4=0, the left hand side is 0. So in the end we obtain, on the RHS, w2+sk⋅w1−logCT2=0 as expected from E2.
Zero-Knowledge
The GS system we constructed is computationally zero-knowledge. Intuitively, it is because commitments are sufficiently hiding, and proof elements are sufficiently randomized. To formally show computational ZK of our system we will (1) provide a simulator that works under a specific alternative CRS setup, (2) show that simulated proofs are indistinguishable from honest ones.
The trick with the simulation is the following one. First, the simulator uses an alternative setup for G2: h1 random, h2=h1u,h3=h1v−1,h4=h1uv. Similarly in G1, g1 is random, g2=g1x, g3=g1y−1 and g4=g1xy. Such a setup is indistinguishable from the honest one under SXDH.
Second, instead of committing to the witness values, the simulator commits to 1∈G1,G2 in both commitments (e.g. D2=g3r2g4s2). Then, the proof elements are kept almost the same, except that now the witness value can't enter V1 from the commitment, so we must cancel CT2 there differently. We solve this by modifying Θ1,Θ2 such that the change only affects V1, but not V2 (these are the only equations in which Θ1,Θ2 are used).
Looking at V1, the extra elements in Θ1,Θ2 will produce exactly CT2: −logCT2(v−1)+ulogCT2uv=logCT2. At the same time, in V2 these extra elements will cancel each other: −logCT2+ulogCT2u=0.
So this simulator produces the right result without using witness at all, at the expense of having access to the CRS trapdoor, while in the honest case the prover must know the witness by soundness (and of course doesn't know the CRS trapdoor).
The next, more involved step, is to show formally is that the distribution of the simulated proof is the same as the distribution of the honest proof --- "fake proofs are good at being fake". Intuitively it holds because there are enough random variables, and the elements in which the simulator "cheats" are still distributed uniformly. Formally, we prove it in the collapsible section.
Collapsible: The Elaborate Proof of Zero Knowlegde
Formally, composable zero-knowledge definition consists of two parts (See Definition 5 in the Groth-Sahai paper). First is the setup indistinguishability: adversary needs to decide between either honest CRS or an alternative one used by the simulator. Second is simulator indistinguishability: the setup in both distributions is subverted, but in one game adversary queries honest proofs, and in another one --- simulated ones.
The first step, setup indistinguishability, is easy to show under SXDH. If an adversary A can tell the difference between honest and simulated setups, we can build a reduction B, in which we merely pass the SXDH challenge (h1,h2,h3,h4) to A as CRS of the form (h1,h2,h3/h1,h4). Obviously, B breaks SXDH then.
Assume the second part of the definition, proof indistinguishability, and thus assume alternative setup (SXDH) in both real and simulated worlds from now on. We now only need to show that for every instance-witness pair, the distributions of honest proofs Π=(Θ,Φ) and simulated proofs Π′ are perfectly indistinguishable. To start with, both Π and Π′ contain exactly the same number of group elements; one can think of these two random variables as tuples of length 12 (containing 4 commitment elements, and 8 proof elements). Moreover, since we assume proofs from both Π and Π′ verify, the verification equations {Vi} restrict elements of these tuples. We will argue that both proof distributions can be viewed as consisting of a set of uniform tuple elements (subset of all proof elements), and other elements being defined from the first set by {Vi}.
Think of {Vi}i as of polynomials, where variables are elements of Π and Π′ (commitments and proof elements). First, fix C1,D1,C2,D2 (the choice is almost arbitrary). It can be easily seen that if we also fix Θ1,Θ2,Φ1 in the equation V1 the only free variable that is left is Φ2. This means that Φ2=F1(D1,D2,Θ1,Θ2,Φ1) for W1 associated with V1 that expresses Φ2 using other elements.
Next, given a fixed C1 we now have two equations V3 and V4 over two free variables Θ3,Θ4, so these two proof elements are also defined deterministically. Consider V3,V4:
Where F1 and F2 in F3 and F4 substitute Φ2 and Φ4 correspondingly.
So far we do not know the distribution of the first eight elements Ξ=(C1,D1,…,Φ3). We will now argue that in both worlds elements of Ξ are distributed independently uniformly at random. This essentially concludes the proof, showing that in both worlds the distribution is exactly the same:
The independence and uniformity of elements in Ξ is simple to see from the following table:
Ξ
Real
Real log
Sim
Sim log
D1
W1h3r1h4s1
w1+(v−1)r1+uvs1
h3r1h4s1
(v−1)r1+uvs1
D2
W2g3r2g4s2
w2+(y−1)r2+xys2
g3r2g4s2
(y−1)r2+xys2
Θ1
pkr1g3αg4β
sk⋅r1+(y−1)α+xyβ
pkr1g3αg4β⋅CT2−1
…−logCT2
Θ2
pks1g3γg4δ
sk⋅s1+(y−1)γ+xyδ
pks1g3γg4δ⋅CT21/u
…+logCT2/u
Φ1
h1r2h3−αh4−γ
r2−(v−1)α−uvγ
same
same
Φ3
h1−αh2−γ
−α−uγ
same
same
C1
h1r1h2s1
r1+us1
same
same
C2
g1r2g2s2
r2+xs2
same
same
Let's take a step back and recall how uniform distributions work, and in particular combine with each other. Intuitively, random variables are independent if none of them can be expressed as a deterministic function of others. Assuming A,B are independently uniform over some Fp, A is independent from A+B also, but A,B,A+B are not mutually independent, since A+B=F(A,B), where F is summing its two arguments. Similarly, A and 5∗A are not independent, and neither are A and 5+A. As a more complex example, if A,B,C,D are independent, so are X=A+B, Y=B+C, Z=C+D. But then X−Y+Z=A+B−B−C+C+D=A+D, so D+A is not independent from X,Y,Z.
We start from the real world. Formally, to prove that the Ξ are linearly independent, we can consider them as 9-dimensional vectors, corresponding to 8 random variables T:=(s1,r1,s2,r2,α,β,γ,δ), and 1 constant. See the "real log" column in the last table, with values considered to be polynomials over γ. For such a set of vectors to be linearly independent, at least one 8×8 submatrix (there are 9 of them) should have nonzero determinant. So we drop the constant row, and compute the determinant of the main 8 columns corresponding to T, which is equal to x3y2u2(2v−1) (see the computation here). It is clear that when the setup is random, the probability of such a determinant to be zero is negligible, since we should guess at least one of the x,y,u,v elements to have a particular value, the probability is <4/p. This shows that Ξ are linearly independent as functions of T. Given that Ξ are themselves linear functions of T, they are independent as random variables. And since it is easy to see that each Ξ can be associated with a unique T, we conclude that in the real world Ξ are independently uniform.
Now, as for the simulated world, take a look at the "Sim" and "Sim log" columns in the last table. It is easy to see that the last four elements Φ1,Φ3,C1,C2 are constructed exactly the same as in the real world. As for the first four elements, we note that the same reasoning applies to them as in the real world: (1) these elements use exactly the same randomizers, so still we can assign a unique Φ element to each of those; (2) linear independence still holds, as we only add and remove constants from these four elements, therefore the matrix we consider is the same.
Thus Ξ is distributed uniformly in both worlds, and thus Π and Π′ are distributed equally in both worlds, and therefore the construction is zero-knowledge.
Note that we in fact need to prove zero-knowledge for the full GS proof system built for allEi equations, and not just for E2. Therefore, in a similar vein, we must provide a simulator for the whole system, and prove that proofs follow the same distribution in both worlds. To simulate the whole proof, we would first subvert a setup, and then run the sub-simulators for each equation separately. A careful reader could have noticed that the alternative setup for G1 could stay the same just for our case of E2 (that is we don't use the fact g3=g1y−1) --- but exactly because we need to simulate in other equations, we need to subvert in both groups. Making the proof distribution indistinguishability statement for all {Ei} simultaneously is also in fact similar to "concatenating" such statements for each Ei. The commitments are reused across different verification equations, but they are distributed similarly in both worlds, and thus the proof elements that depend on them do too.
Bonus: Deriving Proof Structure for E4
In this section we explain how to derive the form of proof elements and verification equations for E4, which we remind has the following form:
e(W2,W3)=e(W2,h1)(E4)
Although the general strategy is the same as for E2, this case is a bit more complicated because E4, unlike E2, includes a product of two witness elements. In particular, in a few places where element grouping can be done in multiple ways, we will let the generic form of GS verification equations (e.g. like in V1…V4) guide our reasoning.
Recall that (C2,D2) is a commitment to w2 and (C3,D3) commits to w3. The equation E4 we target is written in logarithms as w2(w3−1)=0. Expand the witnesses in it using equations for d2 and d3:
(d2−r2y−s2z)(d3−r3v−s3l−1)=0
In this equation, separate constant terms and terms that depend on Di only, because we can check them publicly.
Next step would be to attempt to split the terms on the right hand side into several proof elements. But not any arrangement will work, and therefore we will use the "general form of the proof", trying to mimic V1…V4 for E2. With this in mind, our task is to find Θ1,Θ2,Φ1,Φ2 such that:
θ1u+θ2l+ϕ1y+ϕ2z=d2(d3−1)(E4.V1)
But even with this restriction there exist many ways in defining what proof elements are. Here is how to get the working partition. Leave (r2y+s2z)(d3−1) as it is, and define
ϕ1=r2(d3−1)ϕ2=s2(d3−1)
All the other terms do not depend in fact on y or z! Here is why:
It is easy to check that these Θ1,Θ2,Φ1,Φ2 satisfy E4.V1 as defined above.
Now let's switch to E4.V2, where we need to prove the form of Θ1,Θ2. Again, mimicking E2.V2, we assume it will have the following form:
θ1+θ2u+ϕ3y+ϕ4z=(…)
Where the RHS will contain public instance elements and commitments.
Let's for now expand θ1+θ2u=w2(r3+s3u)=w2c3 (according to how we defined Θ1,Θ2). This is almost a pairing product, except w2 is public (RHS would correspond to e(W2,C3) which reveals W2), so we will again expand it from the equation defining D2:
This naturally defines D2C3 as the RHS of E4.V2, and the following two proof elements:
ϕ3=r2c3ϕ4=s2c3
The verification equation is thus:
θ1+θ2u+ϕ3y+ϕ4z=d2c3(E4.V2)
Switching now to E4.V3. There we need to prove the validity of Φ1,Φ2 in the following form:
ϕ1+ϕ2x+θ3v+θ4l=(…)
Gladly, this is even easier than what we just done for V2:
ϕ1+ϕ2x=(d3−1)(r2+s2x)=(d3−1)c2
This means that θ3=θ4=0, and
θ3v+θ4l+ϕ1+ϕ2x=c2(d3−1)(E4.V3)
Finally, we need the last verification equation to "fix" the form of Φ3,Φ4 (and Θ3,Θ4), deriving which is also easy. Observe that ϕ3+ϕ4x=(r2+s2x)c3=c2c3, therefore:
θ3+θ4u+ϕ3+ϕ4x=c2c3(E4.V4)
(The generic form that includes Θ1,Θ2 is here also because of E2.V4.)
As before, these equations are not yet "randomized" and thus not zero-knowledge. However, adding randomization is done exactly as before. First we add it to Θ1,Θ2,Φ1,Φ2 (so that the randomness cancels in V1) and then propagate to the other set of proof elements. This does not change the form of verification equations, but only the proof elements.