Cryptanalysis of the Algorand Subset-Sum Hash Function (UPDATED 25th June 2022)
Dmitry Khovratovich | June 25, 2022
1. Introduction
Algorand has proposed a compression function which is lattice-ZKP friendly and which they plan to use inside the Merkle-Damgard framework.
The public constants of the function are matrix where . Let us denote the columns of by , . Matrix entries should be pseudorandomly generated.
The compression function processes the -bit input as follows:
with the input interpreted as a -bit value.
The authors claim one-wayness of the compression function, though not mentioning any concrete security level.
2. Generalized birthday problem
The generalized birthday problem was first formulated by Wagner as follows:
Given lists of binary -bit strings find such that
For it is the standard birthday problem and a solution can be found in time (for that big lists). It is less obvious that for one can do better than , concretely in time. The idea can be illustrated for :
- Find \emph{partial collisions} between and i.e. strings that collide in the first bits. This can be done in time by taking elements from both lists and sorting them by the first bits. Put collisions and their components into new list
- Repeat the same for lists and and obtain list .
- Find tuples and such that . This is feasible since both and are zero in the first bits so we need only tuples in both lists to find a collision on the remaining bits.
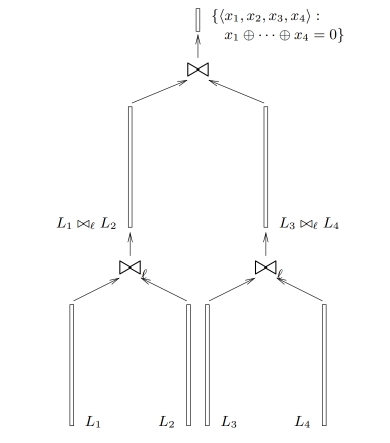
The same approach works for bigger . Note though that there is no such algorithms for 3 lists and the best attack is still .
Finally remark that the process is memory-heavy for . This fact is used in the memory-hard proof-of-work Equihash, used in Zcash.
3. Attack on the Algorand hash
The compression function described in Section 1 is vulnerable to a modification of the generalized birthday attack. Let us find a collision:
We do as follows:
- Split the into 16 64-bit chunks .
- Interpret the output as a 6-tuple where is 32-bit and all other are 96-bit.
- For all pairs , find collisions for in , i.e. solutions for
spending time and space for each using list sorting for birthday paradox. Store all solutions in lists .
- For each find partial collisions between and in :
Note that since both and are 0 in they sum to 0 in it. The number of partial collisions between and is . Store the results in 8 lists .
- We now find partial collisions between pairs of lists in and obtain 4 lists. Then proceed the same way with and get two lists.
- Find a single collision between the two lists in and at cost . It yields
i.e. a collision.
Overall the collision attack costs time (it is not necessary to work on all the lists simultaneously) and thus the overall security of the subset sum hash is at most 98 bits in the time cost model.
UPDATE (25 June 2022)
4. Bug in Section 3 and its fix
The Algorand team has kindly reported us a flaw in Section 3. Concretely, if one merges and in the first step of the attack than due to the linearity of the number of possible pairs is rather than , which makes the search for partial collisions more expensive.
The simple fix to this flaw is to merge instead with , then with , so that the inputs activate different scalars in . When repeating for , one should target different collision bits to avoid having . The rest of the attack remains the same with the same complexity estimate.
5. Algorand internal analysis
In response to our original post, the Algorand team has published an internal analysis. The report investigates the complexity of the Wagner attack implemented on a quantum computer. For collision search the report estimates the quantum attack complexity as time and memory. The same document also gives the complexity of the classical Wagner attack as time and memory, which is a variation (another point on the time-area tradeoff curve) of our attack in Section 3, assuming our bugfix above.
Acknowledgements
We thank Chris Peikert for fruitful discussions that has led to the attack refinements.